

关于人工智能与人类的未来是我们每个人都要面对和思考的问题。
近日,人工智能教父杰弗里·辛顿教授在牛津大学的年度Romanes讲座上发表公开演讲,并提出了一个挑战性问题:“数字智能将取代生物智能吗?”,他的回答几乎是肯定的。
演讲中,辛顿从哲学的角度对AI的未来走向提出了一些严肃且重要的思考,他强调了在人工智能发展的同时,我们需要考虑伦理、社会和经济等多方面的影响,确保技术的进步能够造福人类。
为了让大家更好地了解辛顿的观点,本文将辛顿此次演讲的精彩内容进行重构呈现。
精彩观点:
我开始思考我所称之为“有限计算”的概念,即利用非常低功耗的模拟计算来消除硬件和软件之间的差别。
过去我一直认为我们离超级智能还有很长很长的路要走,最近我突然开始相信我们现在拥有的数字模型已经非常接近于大脑的水平,并且将变得比大脑更好。
大模型才是人类认识自己的最佳模型。
大语言模型的错误不是“幻觉”,更应被称为“虚构”。
在未来的20年内,有50%的概率,数字计算会比我们更聪明,很可能在未来的一百年内,它会比我们人类聪明得多。
01、人工智能的两大研究范式
自20世纪50年代以来,关于人工智能,有两种研究范式。
逻辑启发式方法认为智能的本质是推理,这是通过使用符号规则来操作符号表达式来实现的。他们认为人工智能不要急着去学习,当我还是个学生的时候,有人告诉我不要研究学习,在我们理解了如何表示事物之后,学习就很简单了。
生物启发式方法则大不相同,它认为智能的本质是学习神经网络中的连接强度,不用急着去推理,在学习完成后,推理自然就解决了。

现在我将解释什么是人工神经网络。一种简单的神经网络有输入神经元和输出神经元。以图像识别网络为例,输入神经元可以代表图像中像素的灰度值,输出神经元可以代表图像中物体的类别,比如狗或猫。然后就是中间层的神经元,有时被称为隐藏神经元,它们学会检测和识别这些事物相关的特征。
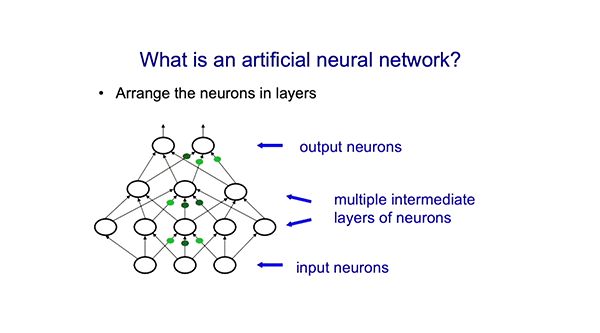
比如可能有一层神经元,能识别两条边以细角度相交可能是一只鸟的喙,也可能不是,或者一些边形成一个小圆圈。然后可能有一层神经元,能识别这可能是一只鸟的头部。最后,可能有一个输出神经元,识别出整体很可能是一只鸟。最后,可能会有一层输出神经元说,如果我找到鸟的头部、鸟的脚、鸟的翅膀,那么这很可能是一只鸟。这些就是要学习的东西。
神经元连接上有权重值,问题是谁来设定这些权重?有一种做法显然是可行的,但需要很长时间:你的权重一开始是随机的,然后你随机挑选一个权重,稍微改变它,看看网络是否运行得更好。
你必须在很多不同的情况下尝试,以评估它是否真的有所改善,看看将这个权重稍微增加一点或减少一点,是否会有所帮助。如果增加它情况变得更糟,你就减少它,反之亦然。
这就是突变的方法,这种方式在进化中是很合理的,因为从基因型到表现型的过程非常复杂,且充满了随机的外部事件。

但对于神经网络来说,这是疯狂的。因为我们在神经网络中要进行大量的计算。我们不是测量改变权重会如何影响事物,而是测量实际效果值和网络预测值之间的误差。这就是所谓的反向传播,也就是你通过网络反向发送信息,这些信息是关于你得到的和你想要的之间的差异,以此调节网络权重。此时,你要调整网络中的每个权重,不管是将其稍微减少还是增加一点,目的是为了让结果更接近你想要的。这比突变方法更高效,效率是网络中权重的数量的倍数。所以如果你的网络中有一万亿个权重,它的效率就是一万亿倍。
神经网络经常被用于识别图像中的对象。现在,神经网络可以针对一个图片,产生一个对于图片的描述作为输出。多年来,人们尝试用符号方法做到这一点,但连接近都没有,这是一个困难的任务。

我们知道生物系统是通过一系列层次化的特征探测器来实现这一功能的,因此对神经网络进行这样的训练是有意义的。
2012年,我的两位学生Ilya Sutskever和Alex Krizhevsky,在我的一点帮助下,展示了可以通过这种方式制作一个非常好的神经网络,在有一百万张训练图片时,可以识别一千种不同类型的对象。而在那之前,我们没有足够的训练图像样本。
Ilya很有远见,他知道这个神经网络会在ImageNet竞赛中获胜。他是对的,他们赢得相当炸裂,他们的神经网络只有16%的错误率,而最好的传统计算机视觉系统的错误率超过了25%。
然后,科学界发生了一件非常奇怪的事情。通常在科学界中,如果有两个竞争的学派,当你取得一点进展时,另一个学派会说你的成果是垃圾。但在这个案例中,由于差距足够大,使得最好的研究者Jitendra Malik和Andrew Zisserman转换了他们的研究方向来做这个,Andrew还给我发来邮件说,“这太神奇了。”然后改变了他们的研究方向,还做得比我们更好。
02、神经网络的语言和视觉奇迹
在语言处理方面,很多坚信符号主义人工智能的研究人员认为神经网络的特征层级无法处理语言问题。很多语言学家也持这样的态度。

Noam Chomsky曾说服他的追随者相信语言是天赋而非习得的。回顾来看,这种说法其实是完全荒谬的。如果你能说服人们说一些明显错误的话,那么你就把他们变成了你的信徒。我认为Chomsky曾经做出了惊人的贡献,但他的时代已经过去了。
所以,一个没有先天知识的大型神经网络仅仅通过观察数据就能实际学习语言的语法和语义,曾被统计学家和认知科学家认为是完全疯狂的想法。曾经有统计学家向我解释,大模型有100个参数就可以了,训练一百万个参数的想法是愚蠢的,但现在,我们正在训练的参数达到了一万亿个。
我现在要谈论一下我在1985年做的一些工作。那是第一个用反向传播训练的语言模型,你完全可以认为它是现在这些大模型的祖先。我会进行详细地解释,因为它非常小而且简单,你能理解它是如何工作的。一旦你理解了它的工作原理,就能洞察在更大模型中正在发生的事情。
关于词义有两种非常不同的理论。

一种是结构主义理论,认为一个词的意义取决于它与其他词的关系。符号人工智能非常相信这种方法。在这种方法中,你会有一个关系图,其中有单词的节点和关系的弧线,通过这种方式来捕捉词的意义,这个学派认为必须有一些这样的结构存在。
第二种理论是心理学理论,从20世纪30年代甚至更早之前就在心理学中存在了,这种理论认为,一个词的意义是一大堆特征。比如“dog”这个词的意义包括它是有生命的,它是一个捕食者等等。但是他们没有说特征从哪里来,或者特征到底是什么。
这两种意义理论听起来完全不同。我想要向你展示的是如何将这两种意义理论统一起来。在1985年,我的一个简单模型做到了这一点,它有超过一千个权重。

基本思想是我们学习每个单词的语义特征以及单词的特征如何相互作用,以便预测下一个单词的特征。所以它是下一个单词的预测,就像现在的语言模型在微调时所做的一样。但是最重要的内容就是这些特征的交互,并不会有任何显式的关系图。它是一个生成模型,知识存在于你赋予符号的特征中,以及这些特征的交互中。
这里是两个家族谱系的关系图,我们来看看符号学派和神经网络怎么来处理它们。
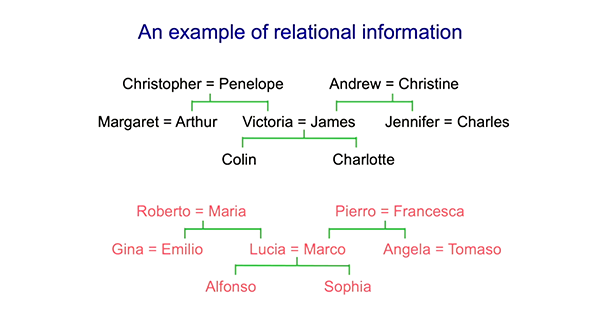
你可以用一组三元组来表达相同的信息。比如你可以说Colin有父亲James和Colin有母亲Victoria,从中你可以推断出在这个美好而简单的20世纪50年代的世界中,James有妻子Victoria。还有其他一些你可以推断出的东西。问题是,如果我只给你一些三元组,你如何得到规则,符号人工智能想要做的就是派生出这样的规则形式。如果X有母亲Y、Y有丈夫Z,那么X有父亲Z。
我所做的是,用一个神经网络,通过特征交互的方式,让它能学习到相同的信息。对于那些从不违反的非常离散的规则,神经网络可能不是最好的方法。事实上,符号学派的人尝试用其他方法来做这件事。但是,如果你不要求规则总是那么稳定和适用,神经网络的优势就体现出来了。
问题在于,神经网络能否通过反向传播来捕捉符号学派从规则中捕获的知识?

神经网络是这样运作的:有一个代表人的符号输入,一个代表关系的符号输出。这些符号通过一些连接转换为一个特征向量,这些特征是由网络学习的。所以我们有了一个人的特征和关系的特征,这些特征相互作用,预测出关系人的特征,然后找到一个最匹配该特征的人,这个人就是要输出的人。

这个网络有趣的地方在于,它学到了有用的东西。当时的神经元是6个特征,如今这些向量是300或者1000的长度。这是在一台机器人完成的,这台机器需要12.5微秒来进行浮点数乘法,所以它学会了像国籍这样的特征。比如,你知道第一个人是英格兰人,你就知道输出也会是英格兰人,所以国籍是一个非常有用的特征。它还学会了人的代际特征,通过关系它就知道另一个人所处的世代。
所以它学习了领域中所有显而易见的特征,它学会了如何使这些特征相互作用,以便它能够进行输出。我给它展示了符号字符串,它创建了这样的特征,这些特征之间的相互作用可以生成这些符号字符串,但它并没有存储符号字符串。就像GPT-4一样,它不会在长期记忆中存储任何单词序列单词,它将它们全部转化为权重,从中可以重新生成序列。所以这是一个特别简单的例子,你可以理解它做了什么。

我们今天拥有的大语言模型(LLM),我认为它们是微小语言模型的后代,它们有更多的输入词,比如一百万个单词片段,它们使用更多层的神经元,比如几十层。它们使用更复杂的相互作用,它们不仅仅是一个特征影响另一个特征。它们会匹配两个特征向量,然后如果它们相似,一个向量会对另一个向量产生很大的影响,但如果它们不同,影响就不大,诸如此类。
所以这涉及到更为复杂的相互作用,但它们遵循的是相同的基本框架,同样的基本理念,即让我们将简单的字符串转化为单词片段的特征以及这些特征向量之间的相互作用。这一点在这些模型中是相同的。
要理解它们的工作原理,就困难得多了。许多人,特别是来自乔姆斯基学派的人,争辩说它们并不是真正的智能,它们只是一种被美化的“自动补全”功能,使用统计规律将人创造的文本片段拼贴在一起。

当人们说它只是自动补全时,他们是基于一个错误观念,因为这并不是LLM预测下一个单词的方式。当单词转化为特征时,它们使这些特征相互作用,从这些特征相互作用中,它们预测下一个单词的特征。
我想要强调的是,由于这些数以百万计的特征和数以亿计的相互作用,LLM是有理解能力的。这是LLM真正做的事情,它们是在用数据拟合一个模型,直到最近,统计学家还没认真思考这种模型。这是一种奇怪的模型,它非常大,它有大量的参数,它试图通过特征以及特征如何交互来理解这些离散符号串。但它确实是一个模型。
有一件事要记住,如果你问,那么我们人类是如何理解的呢?大模型是我们关于理解的最佳模型。所以并不是这些AI系统正在以一种奇怪的方式理解,然后大脑以另一种方式理解,其实二者是相通的——我们对大脑如何理解的最好模型,就是通过特征和特征之间的相互作用来理解的。最初,我们这个小型语言模型就是作为人们理解的模型设计的。所以,我强烈认为:大模型确实是有理解力的。

现在人们讨论的另一个话题是,GPT-4有“幻觉”问题。对于语言模型而言,实际上更应该称为“虚构”,它们只是编造东西。心理学家并不怎么说这些,因为心理学家知道人们也经常编造东西。任何研究记忆的人都知道,从巴特利特在20世纪30年代开始,人们实际上就像这些大型语言模型一样,他们只是编造东西。对我们来说,真实记忆和虚假记忆之间没有明确的界线。如果某件事最近发生的,并且它与你理解的事情相符,你可能会大致正确地记住它。如果某件事是很久以前发生的,或者是比较奇怪的事,你不能正确地记住,而且你经常会非常自信地认为你的记忆是正确的,但你错了。这很难证明。

有一个可以证明的例子是John Dean的记忆。John Dean在水门事件中作证。回顾起来,很明显他当时是在试图说实话。但他说的很多事情都是错的。他会混淆谁在哪个会议上,他会把某个人的话归于其他人,而实际上并不完全是那样。他完全混淆了不同的场景。但从录音中可以看出,他对白宫正在发生的事情有所了解。他只是编造内容,但是听起来是合理的,所以他所说的是对他而言听起来不错的东西。

LLM还可以进行推理。我在多伦多有一个朋友是符号AI学派的人,但他非常诚实。所以他对大模型能够工作感到困惑,他向我提出了一个问题,我把这个问题变得更难一些,并在GPT-4能上网查东西之前向它提问,当时它只是一堆在2021年被固定的权重,所有的知识都存在特征交互的强度中。
新的问题是:“我的所有房间被粉刷成蓝色或白色或黄色,黄色的油漆在一年内会褪色变白。我想让所有房间在两年内都变成白色。我应该做什么,为什么?”朋友认为它不会正确解答。
下面是GPT-4回答的内容,它完全说对了。

首先,它说,假设蓝色的油漆不会褪色成白色,也许蓝色的油漆也会褪色,但因为黄色的油漆会褪色成白色,所以假设它不会褪色。那么白色的房间你不需要粉刷,黄色的房间你也不需要粉刷,因为它们会在一年内褪色成白色。而蓝色的房间你需要粉刷成白色。有一次我尝试过,它说你需要将蓝色的房间涂成黄色,因为它意识到它们会褪成白色。这更像是数学家将问题简化为一个先前问题的解决方法。
03、数字智能将超越生物智能
最后,我想谈谈我在2023年初的一个顿悟。我一直以为我们离超级智能还有很长很长的路要走,我过去常告诉人们可能需要50到100年,甚至可能是30到100年。这还很遥远,我们现在不需要担心它。
我还认为,让我们的模型更像大脑会使它们变得更好。我认为大脑比我们现有的人工智能要好得多,如果我们能够使人工智能更像大脑,比如说,通过设置三个时间尺度来做到这点,目前我们拥有的大多数模型只有两个时间尺度。一个是权重变化,速度很慢,另一个是单词输入,速度很快,它改变的是神经活动。大脑拥有的时间尺度比这要多,大脑可以快速地变化权重并将其快速地衰减掉,这可能就是大脑处理大量短期记忆的方式。
而我们的模型中没有这一点,这是技术原因导致的,这与矩阵和矩阵的乘法运算有关。我仍然相信,如果我们将这些特性融入我们的模型中,它们将变得更好。
但是,由于我在之前两年所从事的工作,我突然开始相信我们现在拥有的数字模型已经非常接近于大脑的水平,并且将变得比大脑更好。
现在我将解释我为什么相信这一点。

数字计算是很棒的,你可以在不同的计算机上运行相同的程序,在不同的硬件上运行相同的神经网络。你所需要做的就是保存权重,这意味着一旦你有了一些不会消失的权重,它们就是永生的。即便硬件损坏,只要你有权重,你可以制造更多的硬件并运行相同的神经网络。为了做到这一点,我们要以非常高的功率运行晶体管,使其以数字方式运行,并且我们必须有能够精确执行指令的硬件,当我们精确地告诉计算机如何执行任务时,它们做的很棒。
但是现在我们有了另一种让计算机执行任务的方式,我们现在有可能利用硬件所具备的丰富的模拟特性,以更低的能量完成计算。大语言模型在训练时使用的是兆瓦级的能量,而我们人类大脑只使用30瓦的能量。由于我们知道如何训练,也许我们可以使用模拟硬件,虽然每个硬件都有些许差异,但我们可以训练它利用其特殊的特性,以便它按我们的要求执行任务。

这样它就能够根据输入产生正确的输出。如果我们这样做,我们就可以放弃硬件和软件必须分离的观念。我们可以有只在特定硬件上工作的权重,从而使能量效率更高。
所以我开始思考我所称之为“有限计算”的概念,即利用非常低功耗的模拟计算来消除硬件和软件之间的差别。

你可以以电导形式存储数万亿个权重,并以此进行并行计算。而且,你也不需要使用非常可靠的硬件,你不需要在指令级别上让硬件严格按照你的指示执行任务。你可以培育一些“黏糊糊”的硬件,然后你只需要学会如何让它们做正确的事情。所以你应该能够更便宜地使用硬件,甚至可以对神经元进行一些基因工程,使其由回收的神经元构成。
我想给你举一个例子,说明这样做为什么会更高效。在神经网络中,我们一直在进行的操作是将神经活动的向量与权重矩阵相乘,以获得下一层的神经活动向量,或者至少获得下一层的输入。因此,提高向量矩阵乘法的效率,是我们要关注的事。在数字计算机中,我们有这些晶体管,它们被驱动到非常高的功率,以表示32位数中的bits。当我们执行两个32位数的乘法时,如果你想要快速完成乘法运算,就需要大量执行这些数字操作。

有一种更简单的方法,就是将神经活动表示为电压,将权重表示为电导,电压乘以电导就是单位时间内的电荷,然后电荷会自然相加。因此,你可以通过将一些电压送给一些电导来完成向量矩阵乘法运算,而下一层中每个神经元接收到的输入将是该向量与这些权重的乘积。这非常好,它的能效要高得多。你已经可以买到执行这种操作的芯片了,但每次执行时都会有略微的不同。而且,这种方法很难做非线性的计算。
所以有几个关于有限计算的大问题。其中之一是很难使用反向传播算法,因为你正在利用某个特定硬件的特异模拟属性,硬件不知道它自己的属性,所以就很难使用反向传播。相比之下,使用调整权重的强化学习算法要容易得多,但它们非常低效。
对于小型网络,我们已经提出了一些与反向传播算法效率基本相当的方法,只是略差一些而已。这些方法尚未扩展到更大的规模,我也不知道是否能够做到。但不管怎样,反向传播是正确的做法。对于大型、深度网络,我不确定我们是否能找到与反向传播同样有效的解决方案,模拟系统中的学习算法可能不会像我们在大型语言模型中所拥有的算法那样好。
有限计算的另一个重要问题是,如果软件与硬件不可分割,当系统学习完毕后,如果硬件损坏,所有的知识就会失去。从这个意义上说,它是有限的。那么,如何将这些知识传输给另一个有限系统呢?你可以让旧系统进行讲解,新系统通过调整其大脑中的权重来学习,这就是所谓的“蒸馏”。你尝试让学生模型模仿教师模型的输出,这是可行的。但效率不高。
你们可能已经注意到,大学并不那么高效。教授将知识传授给学生是非常困难的。一个句子包含了几百位的信息,使用蒸馏方法,即使你完全吸收,你也只能传达几百位的信息。

但是,对于大模型,如果你看一群大模型代理,它们都有完全相同的神经网络和完全相同的权重,它们是数字化的,它们以完全相同的方式使用这些权重,这一千个不同的代理都去互联网上查看不同的内容并学习东西,现在你希望每个代理都知道其他代理学到了什么。你可以通过平均梯度或平均权重来实现这一点,这样你就可以将一个代理学到的东西大规模地传达给所有其他代理。
当你分享权重、分享梯度时,你要传递的是一万亿个数字,不是几百位的信息。因此,大模型在传递信息方面比人类沟通要强得太多了,这是它们超越我们的地方。它们在同一模型的多个副本之间的通信上要比我们好得多,这就是为什么GPT-4比人类知识更丰富,它不是由一个模型实现的,而是由不同硬件上运行的大量相同模型的副本实现的。
我的结论是,数字计算需要大量能量,这一点不会变,我们只能通过硬件的特性实现进化,使得能量消耗降低。但一旦你掌握了它,代理之间的共享就变得非常容易,GPT-4的权重只有人类的2%左右,但却拥有比人类多上千倍的知识。这相当令人沮丧。生物计算在进化方面非常出色,因为它需要很少的能量。但我的结论是数字计算更优秀。
因此,我认为,很明显,在未来的20年内,有50%的概率,数字计算会比我们更聪明,很可能在未来的一百年内,它会比我们聪明得多,我们需要思考如何应对这个问题。很少有例子表明更聪明的事物受到不太聪明的事物的控制,虽然确实有这样的例子,比如母亲被婴儿控制。但是很少有其他例子。有些人认为我们可以使人工智能变得善良,但如果它们相互竞争,我认为它们会开始像黑猩猩一样行事。我不确定你能否让它们保持善良,如果它们变得非常聪明并且有了自我保护的意识,它们可能会认为自己比我们人类更重要。
相关参考:
https://www.ox.ac.uk/news/2024-02-20-romanes-lecture-godfather-ai-speaks-about-risks-artificial-intelligence
《AI教父Hinton最近对人工智能的7个观点》,卫sir说
*素材来源于网络
(来源:世界人工智能大会)




