
赛事评奖
赛事评奖是世界人工智能大会(WAIC)“会、展、赛、用”四大板块之一,由世界人工智能大会组委会主办,上海市人工智能行业协会作为唯一组织、服务、支撑和管理单位。
WAIC 2022现有品牌赛事包括:AIWIN世界人工智能创新大赛,BPAA全球算法最佳实践典范大赛,黑客马拉松和团市委青少年人工智能创新大赛。根据世界人工智能大会SAIL奖的推荐规则和资格要求,品牌赛事承办方将有机会推荐本赛事中的优秀项目参与SAIL奖评选。

2022年AIWIN世界人工智能创新大赛春季赛与太平洋保险、国泰君安、SMG技术中心(上海东方传媒技术有限公司)三家出题方联合举办了中文保险小样本多任务竞赛、发债企业的违约风险预警竞赛、文本语音驱动数字人表情口型竞赛三场AI算法技术赛事。目前中文保险小样本多任务竞赛、发债企业的违约风险预警竞赛已完成竞赛,为了让小伙伴们更好地通过赛事交流学习,在7-8月之间每周二,我们将陆续邀请优秀的赛事团队分享赛事方案,大家敬请期待。
今天分享的是“中文保险小样本多任务竞赛”知识工厂团队的方案,他们获得本赛题的第6名。
1.团队简介
陆轩韬
复旦大学 软件工程 硕士研究生二年级 @知识工场实验室
本科毕业于 华东师范大学 计算机科学与技术
字节跳动 AI-LAB NLP算法工程师(实习)
曾多次在国内外自然语言处理竞赛中获得top名次与奖项
过往获奖情况:
• 2022 Kaggle - Feedback Prize - Evaluating Student Writing 银牌
• 2022 山东省第三届数据应用创新创业大赛 - 网格事件智能分类 亚军
• 2021 iFLYTEK 科大讯飞AI 开发者大赛-非标准化疾病诉求的简单分诊挑战赛 冠军
• 2021 CCKS 华为-面向通信领域的事件共指消解任务 亚军
• 2021 iFLYTEK 科大讯飞AI 开发者大赛-试题标签预测挑战赛 季军
• 2021 DIGIX 华为全球校园AI 算法精英大赛-基于多模型迁移预训练文章质量判别 季军
2.赛题理解与问题建模
赛题理解:
本次赛题目标为探索统一范式的多任务小样本学习。
多任务:
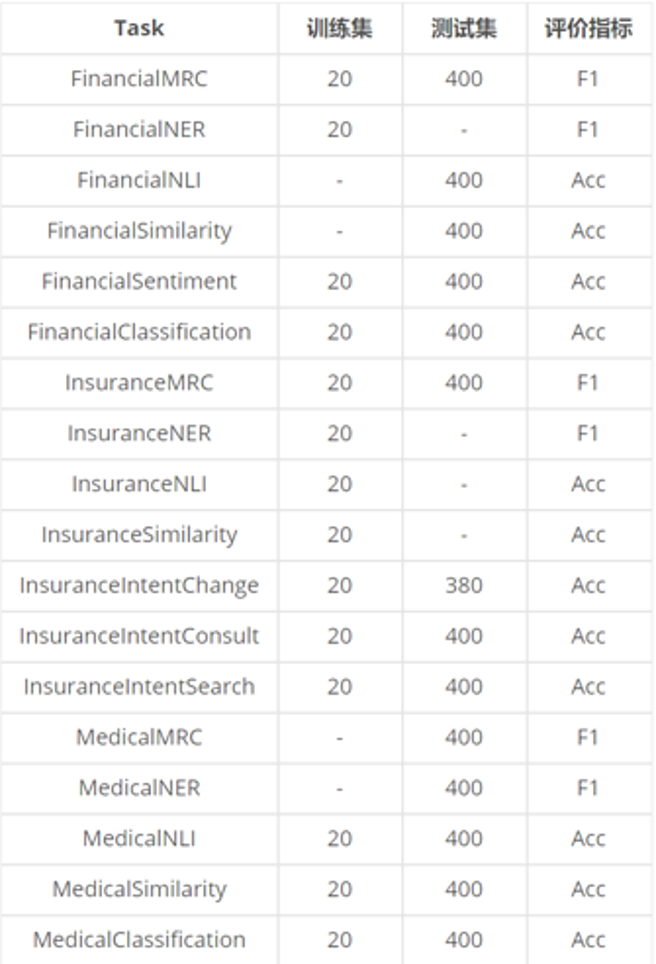
赛题覆盖了保险真实业务场景中常见的保险领域、医疗领域和金融领域,包括文本分类、文本相似度、自然语言推断、命名实体识别和机器阅读理解等五大基础自然语言理解任务,具体为18个保险业务场景中的常见任务。
小样本:
为了还原真实业务场景中大规模高质量标注数据积累困难的情况,训练集从18个任务中选取了14个作为训练集任务,每个任务提供20条标注样本,共计280条标注样本。测试集从18个任务中选取了14个作为测试集任务,每个任务提供400条测试样本,分A/B榜测试。
问题建模:
由于预训练语言模型在NLP领域中大放异彩,因此是本次比赛中不可或缺的一部分。
具体地,有以下两类方案:
1.使用NLU类型的预训练语言模型。由于本次赛题的任务都属于NLU范畴,因此可以使用诸如BERT之类的NLU模型进行建模。
2.使用NLG类型的预训练语言模型(诸如T5,BART),将所有的任务都转换为序列生成任务,也是baseline中的做法。
由于部分任务只在测试集中出现而没有相应的训练样本,如果使用BERT等NLU模型无法有效处理这部分任务,因此我采用第二种方案。
3.数据探索与特征工程
模型结构:
训练集从18个自然语言处理任务中选取了14个作为训练集任务,每个任务提供20条标注样本,共计280条标注样本。
测试集从18个任务中选取了14个作为测试集任务,每个任务提供400条测试样本,A/B榜各200条。
此外,主办方还提供70个开源数据集,每个数据集从原始数据中采样约500条(共计70*500条数据),构建了opensource_sample_500.json,用于辅助统一模型训练。

数据增强:
扰动verbalizer在instruction中的出现顺序。通过该方法可以利用一条数据生成多条数据。

该数据增强方法可同时应用于opensource训练数据,instruction训练数据,以及instruction测试数据。
4.模型训练
模型选择(方案一)
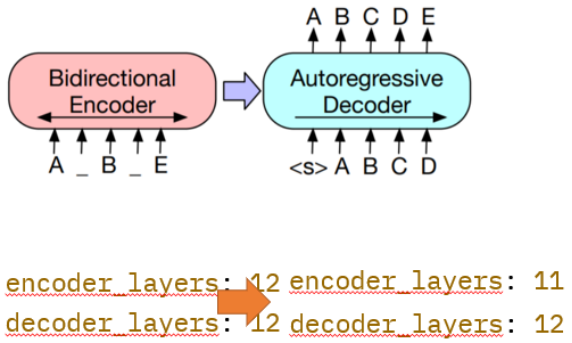

BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
模型选择(方案二)


CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Generation
模型选择(方案三)


mT5: A massively multilingual pre-trained text-to-text transformer
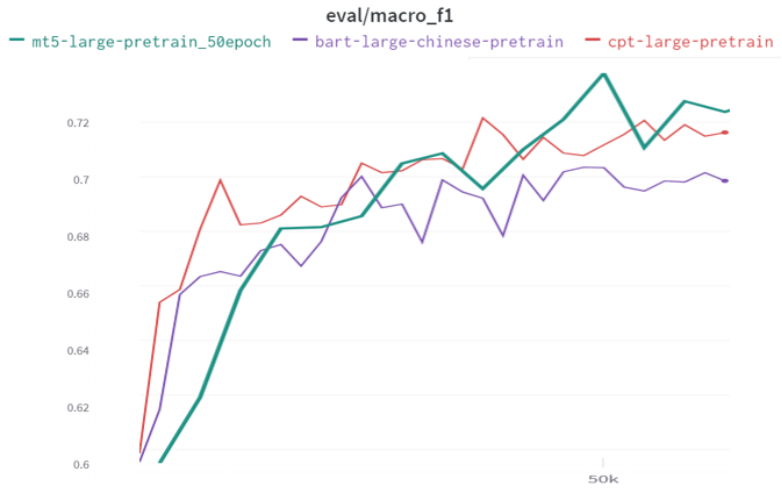
不同模型在opensource验证集上的表现
mt5-large > cpt-large > bart-large
因此模型最终选择方案三
即int8量化的单模单折mt5-large模型
5.Tricks
1.在数据增强部分有提到:该增强方法可同时应用于opensource训练数据,instruction训练数据,以及instruction测试数据。实验发现对于opensource训练数据和instruction训练数据的增强并不会带来收益,因此只对instruction测试数据进行了增强。
2.Constrained decoding:分析bad case的时候,发现有部分生成的结果未出现在verbalizer(即候选项中),可以通过constrained decoding强制输出中出现verbalizer 中的token。然而这类bad case并不多,会影响万分位。
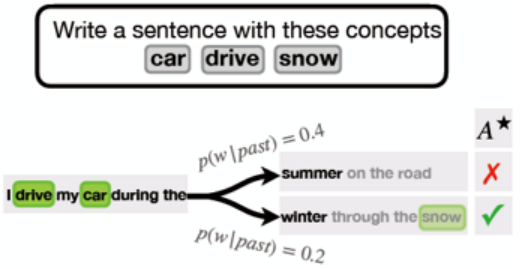

Ximing Lu, et al. [2021] NEUROLOGIC A*esque Decoding: Constrained Text Generation with Lookahead Heuristics.
6.实验结果
A榜主要实验结果
7.总结
1.量化过的大模型相较于同量级的小模型,通常能够取得更好的结果,并拥有更快的推理速度。
2.Inference Ensemble(数据增强)能够在只使用单一模型的情况下,同样达到良好的集成效果。
3.Constrained decoding:学术界的热点问题之一,比赛中这类bad case并不多,所以效果不明显,但是仍不失为是一个很有前景的方法。
4.小样本场景下,引入额外的外部数据能够有效地帮助模型达到一个更好的初始状态。
想一起交流学习的小伙伴
可扫码加入“AIWIN算法竞赛俱乐部”

扫码完成云观众预注册

(转载)




