
2016年深度学习技术不断推动着计算工业的前进,专家称在2017年人工智能领域将需要更快速,更强劲的“推理”引擎来强化深度神经网络。
现有的深度学习系统动用的是大型计算的优势,借助网络以及大数据来进行训练和学习,然后再对接大型计算系统来完成它的目标任务。
不过,这种学习方式在执行效率方面很显然不适合嵌入式系统(也就是包含,汽车,无人机,包括物联网设备,工业控制器等等)这些设备往往受到能源,带宽以及存储器大小方面的限制。
把深度神经网络放到终端设备中为技术创新提供了非常大的可能性
就在几个月前Movidius CEO,RemiElquazzane曾表示,"人工智能在边缘计算上的投放,将会是一个趋势"

Marc Duranton
当问及如何让AI在边缘计算方面发挥能力的时候,集成电路设计以及嵌入式软件部门的CEA架构研究员Marc Duranton 阐述了其独道见解,安全,隐私性和商用化这三点是快速进入了工业领域处理末端数据的关键。Duranton 发现“短时间内将数据变为信息”需求正在增长。
再比如无人汽车,如果安全性是这种技术设计最终目的,那么这种无人的功能设计不应该完全依靠——全时间的实时网络连接。可以想象如果一个上年纪的人在家中摔倒,这起事件就应该在本地侦测并得到确认。私密性是一方面重要原因,而不依赖家中的10个摄像头来传输图像激活报警其实也是为了降低能耗以及数据规模,Duranton补充说
竞赛开始了
芯片供应商从多方面了解到市场对更好的推理引擎的增长需求。
类似于Movidus,Mobileye 以及 英伟达 这样的半导体厂商已经在超低功耗领域方面展开了竞争,更高的硬件加速表现可以让嵌入式设备能够拥有更好的学习能力。
Duranton 认为,这些公司在SOC方面所做的工作说明了推理引擎已经成为了许多半导体公司在后移动时代的新的研究方向
谷歌的Tensor 处理单元即TPUs在今年年初的发布标志着工程领域对机器学习类芯片的创新已经达到了如饥似渴的程度。
在发布会上,这家搜索巨头公司形容TPUs提供了一个“比商用FPGA和GPU芯片高出一个数量级的单位瓦特性能。”谷歌展示了这款被装载在打败人类围棋冠军的阿尔法狗系统的加速器,然而却从来不曾谈论TPUs的结构细节,也不会将TPUs出售给商用市场。
很多SOC设计者认为谷歌的这一举动让机器学习系统设计方面更趋于定制化的结构,但是在他们设计定制化的芯片时,又对谷歌芯片的结构感到好奇。更要命的是,设计者们想要知道现在对于不同的硬件平台是否已经能够有评测工具来对于深度神经网络DNN的好坏进行评测和测量。
工具正在到来
CEA已经准备好了应对不同硬件架构的推理技术的开发,并且开发了一个软件框架,叫做 N2D2(有点类似星球大战的机器人的名字R2D2)它能够使设计者探索并生成DNN结构。开发这个工具可以帮助DNN来选择更加合适的硬件。
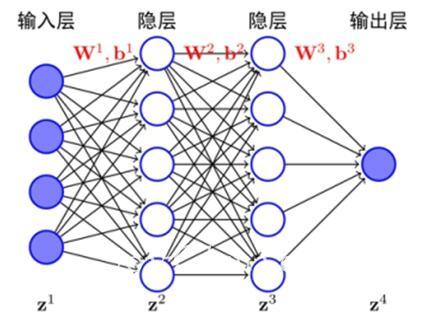
DNN深度学习结构
N2D2将能够在2017年第一季度实现开源,Duranton承诺道。
N2D2这个新工具的关键在于不仅能够非常精准识别出并比较不同硬件,还可以在处理时间,硬件成本,以及能源消耗这几个重要方面实现比较。Duranton认为这几点都非常重要 ,因为不同的应用对于深度学习来在不同的硬件环境中实施中时可能会需要不同的参数。
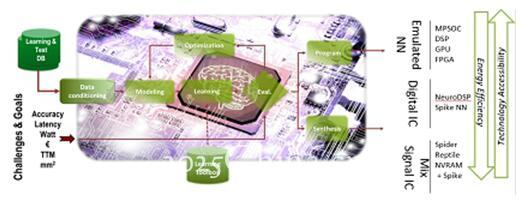
N2D2的工作方式(来源:CEA)
N2D2提供了一系列商用常规硬件的测试,包括CPU,GPU以及FPGA多核以及多芯片协作的测试
边缘计算方面的障碍
作为一个研究机构,CEA已经对怎样的让深度神经网络更好地融入边缘计算进行了反复研究。关于DNN在边缘计算方面的障碍,Duranton认为,浮点服务器解决方案是不能够使用的,除了电力,体积,延迟方面的限制,其他的限制还包括了MAC,带宽和板载芯片的内存空间的等因素。
那么“以整数替代浮点”是首要考虑的事情,那么其它还要考虑什么呢?
Duranton相信特殊的架构能够采用新的编码,比如脉冲尖峰编码(spike coding)
当CEA的研究者们对于神经网络的特性进行研究时,他们发现这些特性对计算错误具有先天的容错性。这就让它们成为了模糊计算方面非常好的备选。
所以如果是这样,可能二进制编码不再那么必要。这对于时间编码(temporal coding)来说是一个好消息——就比如脉冲尖峰编码(Spike coding)——能够使边缘端的计算能效方面产出比更高,Duranton 解释
脉冲尖峰编码是具有相当的吸引力,因为尖峰被编译时或者在一个基于事件的系统中都展示了数据如何在真实的神经系统中进行编译。更进一步说明,基于事件的编码是可以与精密传感器和前处理技术进行相互匹配的。
这样的编码更能让研究人员来构建一个体积更小能耗更低的硬件加速器并且用于一个装备有混合模拟以及数字应用的神经系统当中。
也有一些其他因素可以帮助在边缘计算方面加速构建DNN结构
CEA就仔细考量了调整神经网络架构转换成边缘计算的潜力,包括用 Squeeze Net 来代替 Alex Net(两种神经网络结构的名称)Duranton特别强调。 据说SqueezeNet 能够完成相当于Alex Net 级别精度的50倍小的参数。Duranton也认为这种简化是边缘计算所需要的,在拓扑结构上是使Macs数量得到降低。
在Duranton看来,研究目标是将“典型的”DNN结构“自动转换到嵌入式”网络当中。

Alexnet结构
P-Neuro,一个过渡时期的芯片
CEA的真正野心在于发展神经元形态的电路。这家研究机构相信这样的芯片是从传感器的近端来提取有用信息进行深度学习的一个有效补充。
在达到研究目标之前,CEA试探了很多过渡性步骤。比如N2D2开发工具就是芯片设计者们开发“高水平能效功耗比TOPS(TOPS每秒亿万次计算)DNN”定制化解决方案的关键
未来,那些指望在边缘计算上利用DNN的人可以选用手头上的硬件去测试,为此,CEA提供了一个功耗极低的可编程加速器,叫做P-Neuro(P神经)
现有的P-Neuro 神经网络处理单元基于FPGA构建,而且,根据Duranton所说CEA正在将这种FPGA转换至ASIC
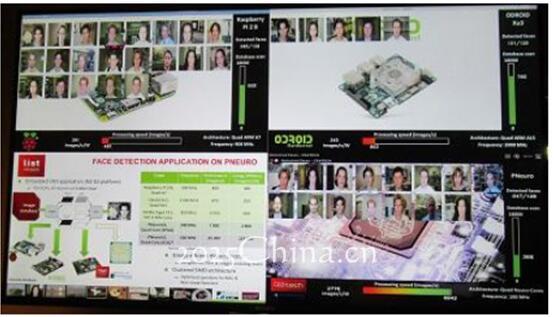
当P-Neuro样本demo遇到 嵌入式CPU
在CEA的实验室中,Duranton展示了一个面部侦测的卷积式神经网络(CNN,convolutional neural network,模拟人类大脑结构)应用,运行于基于FPGA的 P-Neuro上。 这个P-Neuro 的demo被用于与嵌入式CPU(树莓派Raspberry Pi的四核ARM处理器以及安卓系统上的三星猎户座SOC)进行比较,并同时运行相同的嵌入式CNN应用;目标任务是从一个数据库中调出的超过18000张图像当中进行人脸特征提取。
如图所示P-Neuro识别速度是6942张图每秒,能效达每2776张图像仅用一瓦特

看P-Neuro是怎样毙掉嵌入式CPU和GPU的(来源CEA)
对比嵌入式GPU(如英伟达的Tegra K1), 基于 FPGA的P-Neuro 可以运行在100MHZ并被证明效率上快了一到两倍,能效方面更是提供四到五倍
P-Neuro 建立在SIMD架构的基础上,并以内存层级结构的优化以及互联为特点
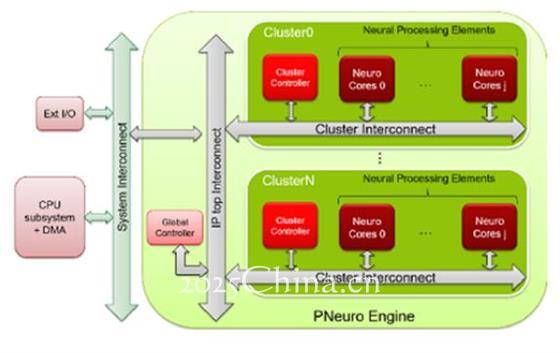
P-Neuro(来源CEA)
欧盟项目
“就CEA研究者来说,P-Neuro “是一个短期芯片”Duranton 强调。P-Neuro 是用二进制编码嵌入在一个完整的CMOS器件上。该项目组也同时在进行在一个完整CMOS设备上运行脉冲尖峰编码的工作。
为了能充分利用先进设备来突破密度和功耗的问题,该团队也已经设定了更高的目标
同时欧盟作为EU地平线2020计划的一分子,正在寻找“拟制造一款芯片来实施神经元架构支持最顶级的机器学习并且支持基于脉冲尖峰(spike,nerve impluse=spike)的学习机理
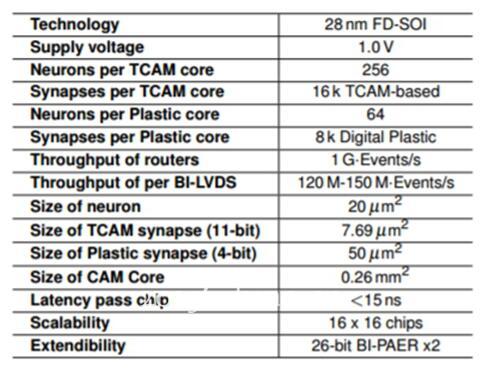
这个项目的名称叫做NeuRAM3, 据称其芯片将具备超低功耗,可测量以及高可控性的神经架构“项目的目的在于能够在特定应用中比常规数字化方案节约50倍的能耗。

神经元形态处理器
神经形态处理器基础说明(来源: Prof. Giacomo Indiveri)
CEA是一个深度融合的项目,CEA的自主研究目标是与NeuRAM3项目来说几乎是相同的。这就包含了FD-SOL单片集成3D技术的开发,以及RRAM存储器突触元素的使用。
与IBM的叫做TrueNorth 脑力激发系统相比较,NeuRAM3项目的新混合信号多核新神经形态设备应该能够大幅降低能源的消耗。

与IBM的TrueNorth对比
其它NeuRAM3项目的参与者包括了:IMEC,以及IBM苏黎世,ST微电子,CNR,IMSE,苏黎世大学和德国雅各布斯大学
2025china原创,转载请注明!
ZERO1整理编译
(转载)




